Hierarchical Planning for Long-Horizon Manipulation
with Geometric and Symbolic Scene Graphs
Yifeng Zhu1,2 Jonathan Tremblay2 Stan Birchfield2 Yuke Zhu1,2
1The University of Texas at Austin 2NVIDIA
Paper
Abstract
We present a visually grounded hierarchical planning algorithm for long-horizon manipulation tasks. Our algorithm offers a joint framework of neuro-symbolic task planning and low-level motion generation conditioned on the specified goal. At the core of our approach is a two-level scene graph representation, namely geometric scene graph and symbolic scene graph. This hierarchical representation serves as a structured, object-centric abstraction of manipulation scenes. Our model uses graph neural networks to process these scene graphs for predicting high-level task plans and low-level motions. We demonstrate that our method scales to long-horizon tasks and generalizes well to novel task goals. We validate our method in a kitchen storage task in both physical simulation and the real world. Our experiments show that our method achieved over 70% success rate and nearly 90% of subgoal completion rate on the real robot while being four orders of magnitude faster in computation time compared to standard search-based task-and-motion planner.
Geometric and Symbolic Scene Graphs
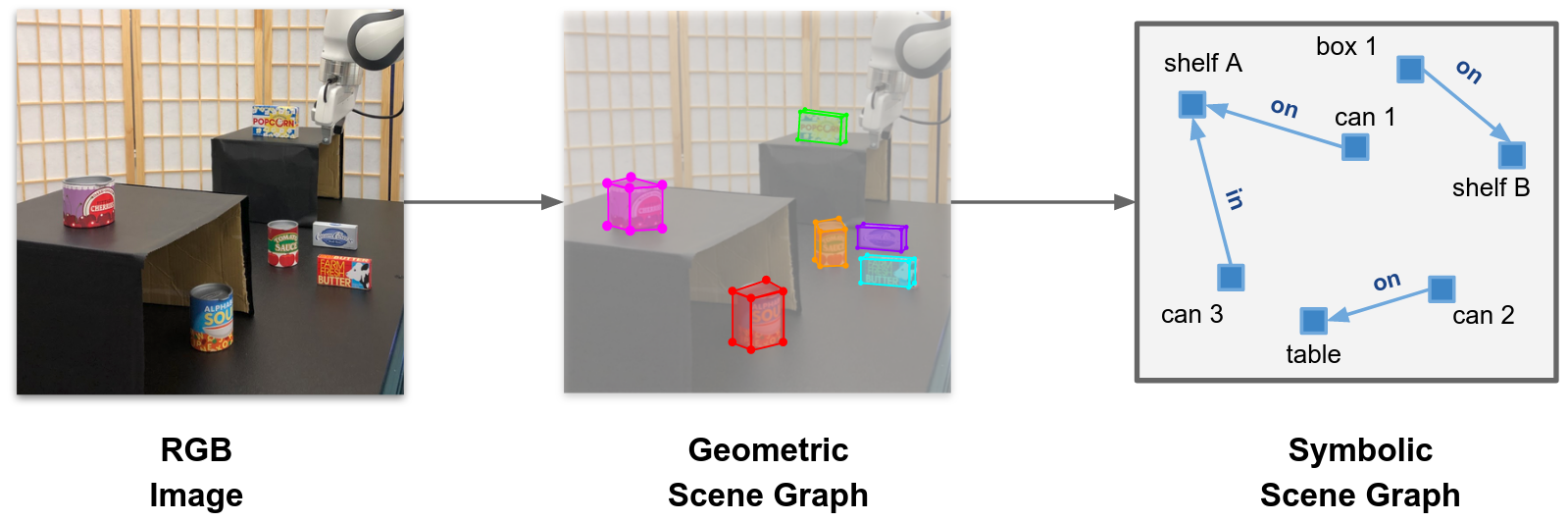 |
We construct a two-level abstraction of the manipulation scene. We first obtain a geometric scene graph by estimating 6DoF poses of objects in the scene. Then we map the geometric scene graph into a symbolic scene graph, representing topological relations among objects.
Method Overview
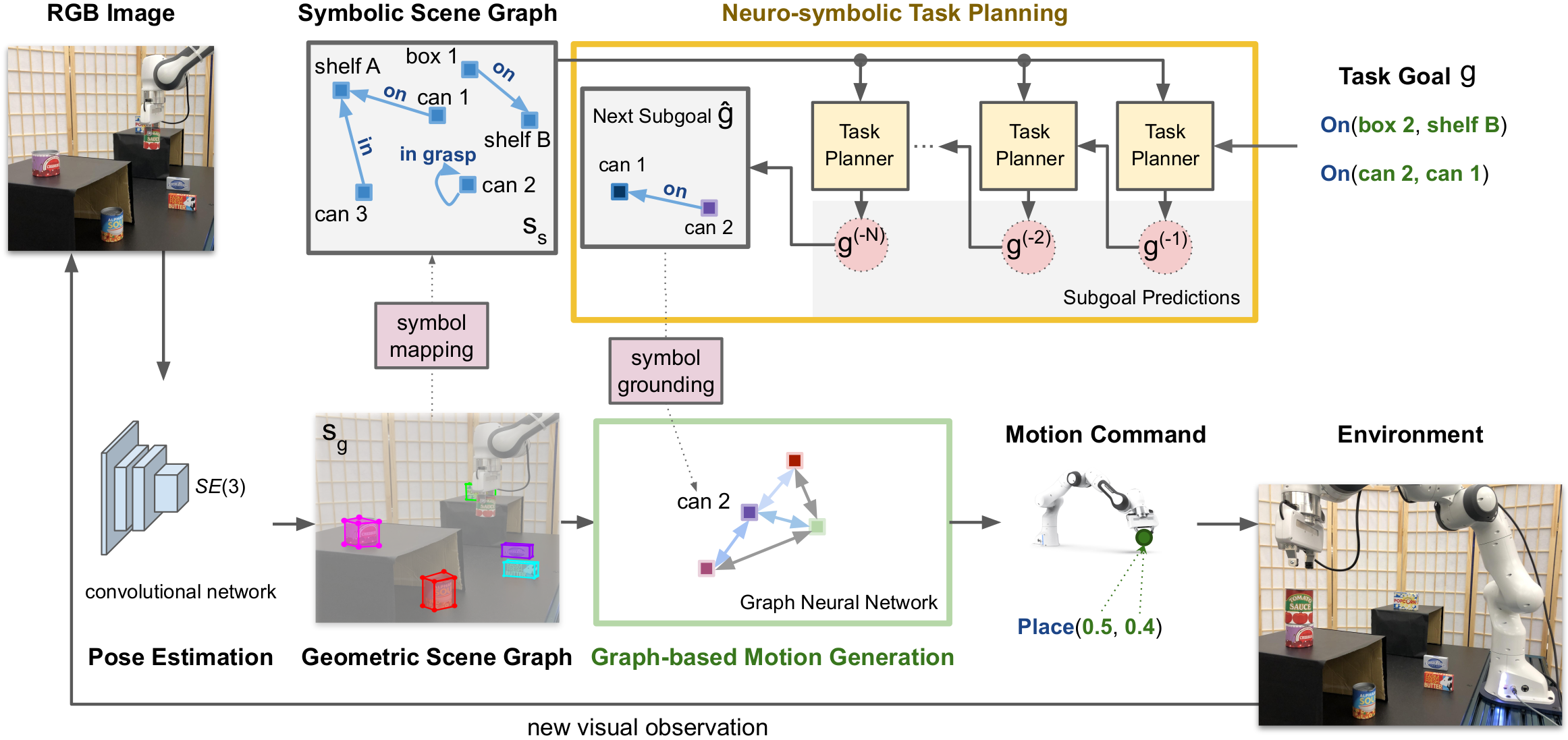 |
Our method first extracts both geometric and symbolic scene graphs from the manipulation scene. Then we conduct visually grounded hierarchical planning on this hierarchical representation. The planning aproach consists of Neuro-symbolic Task Planning and Graph-based Motion Generation.
Training Data
Training data for task planning and motion generation are provided in simulation. The simulation is based on PyBullet physics and a ray-tracing rendering library ViSII. Following snapshots are examples of demonstration provided in simulation.
 |
 |
 |
 |
Real Robot Results
We evaluate our algorithm on the real robot. In this example, we visualize both the symbolic scene graph and the next subgoal to execute.
We also evaluate on much longer horizons on real robots.
Acknowledgements
We would like to thank Guanya Shi for providing an improved version of DOPE. We also would like to thank NVIDIA AI-Algorithm team for providing valuable internal feedback to the paper.
